
The Missing Pieces from Andrej Karpathy LLM Wiki System
Andrej Karpathy recently published a concept for an LLM-native wiki.
He describes a knowledge base where AI doesn’t just retrieve information but actively maintains, cross-references, and compounds it.
I recognized two big problems:
- A fully AI-maintained system can only organize in a way that is recognizable to the user after substantial setup by the user.
- In the absence of information architecture the wiki will quickly grow past the point of efficiency it set out to achieve in the first place.
So, here is my contribution to the idea.
What Karpathy Gets Right
RAG is a significant improvement over giving your LLM every context document it might need at some point. I think of it as the AI-equivalent of “just-in-time manufacturing.” Less waste, faster output.
Karpathy correctly points out that most RAG systems lack an answer for how to replace old information, with new information, at scale.
Additionally, Karpathy is right to point out that the key bottleneck is the human user handling the organization tasks. A source not properly integrated as context is effectively invisible.
Karpathy’s wiki approach lets AI write back, integrating new information into existing understanding, filing strong answers for reuse, letting knowledge build on knowledge instead of starting from scratch with every new conversation.
The Missing Piece from Karpathy’s idea is Routing Architecture
As I understand it…
Karpathy’s index.md is the map of the namespace. It’s AI-maintained, which means it’s organized according to how the AI would organize it, not necessarily how the user would organize it. Most of the time this wouldn’t be a problem, but it’s also more than just edge cases where it does.
So, the first problem is the words.
The second problem is the lack of structure, which means this idea falls apart at scale. RAG is intended to be more efficient, but once your index gets too big, the LLM is still searching through far too many lines to find what it’s looking for.
I believe the missing pieces are routing tables and non-hierarchical taxonomies.
Let me explain with a simple example.
If you were walking into someone’s house and looking for a spatula, you would presumably first look for the kitchen. Next, you would scan the kitchen for the most likely places to find one, likely near the stove. Do this, and you would likely find it pretty quickly.
In this case you might have: 1st Floor > Kitchen > Drawers near stove > Spatulas
By contrast, imagine that instead you either need to walk in and begin searching in every room of the house, or look through a giant index listing every single item in the house.
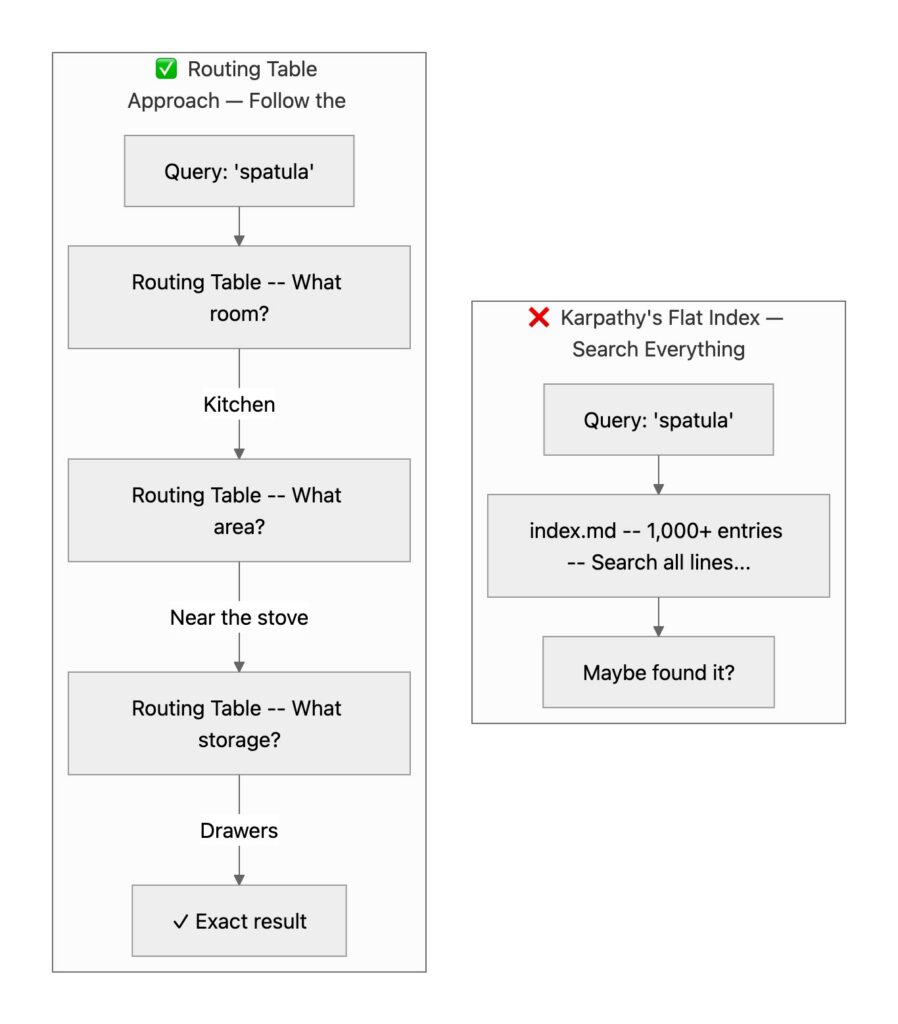
Which is more efficient?
Additionally, back to the first problem, what if you have always called a spatula “the flat flippy thing” or “the pancake flipper?”
A good organizational system needs to assign multiple ways to move closer to the information you are looking for and needs to have enough slack in the system to support your unique use of language.
My Contribution
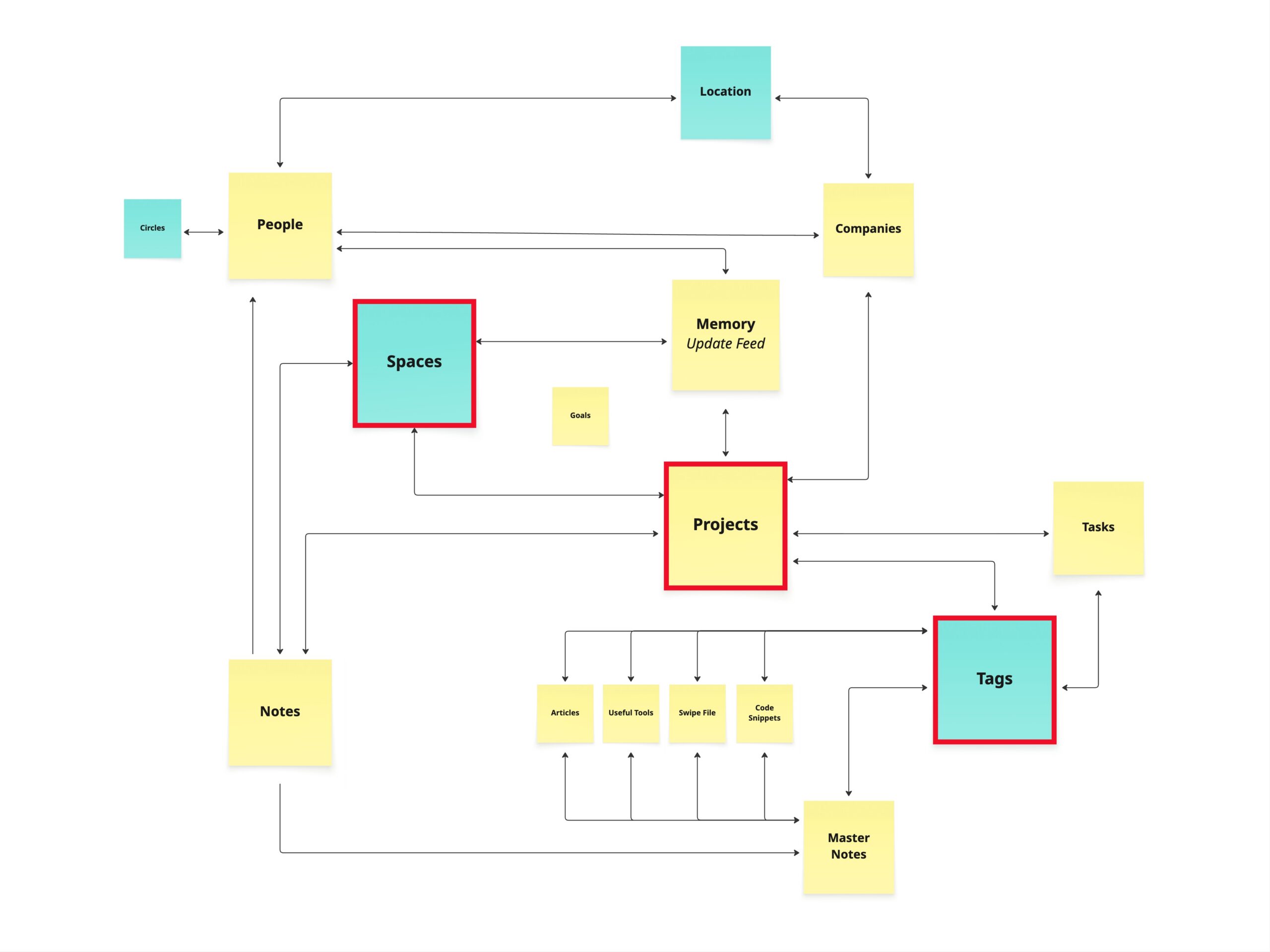
I’ve been using Notion as my knowledge management system for almost a decade now. And even before Notion AI, I knew that I needed a system where “everything has a home” so that I could easily find whatever I needed. This developed into what I call The SuperBrain OS.
This isn’t a pitch for my template (though you should be it because it’s awesome), I’m just using it to explain how it aligns with what Karpathy was eluding to while introducing an element that I feel is missing.
The SuperBrain OS doesn’t use one big wiki. It uses multiple databases, each with a defined purpose, connected to other databases through relational fields. Each database serves can serve as a taxonomy for the databases it is connected to.

When the Tags databases is connected to Notes, Tasks, and Articles, I’m then able to find any of those via the Tag. Add in other relations and now you can combine fields to find what you are looking for — just like my spatula example. But by having a non-hierarchical taxonomy, I can now quickly find bathroom towels, kitchen towels, and beach towels.

These relations, along with routing tables are the first layer of the index. This mean that my AI system can follow 2 or 3 layers before searching for the information, and is both more efficient in finding it, and more likely to find exactly what I was asking for. And this same system works in reverse for the AI to maintain my knowledge system.
Chunks > Piles
When developing my system, I chose a number of different categories that I felt best represented the big buckets that information falls into. Then, within those databases, I added some light refining categorization, as well as relations to some other big categories.
This creates a series of progressive chunks that shortens the distance from query to retrieval. Nothing ever gets so big that it can’t be grouped.
- Instead of an index with 100 lines, it’s 10 groups with 10 items each.
- Instead of an index with 1,000 lines, it might be 20 groups, with 50 items each broken into 5 groups of 10.
As the dataset grows, having a way finding system becomes critical. My approach has been to build that from the beginning and plug the AI into it.
You design the structure, the AI maintains it
Our knowledge is personal. It’s informed by our values, our decisions, our frameworks. Therefore, the organizing logic needs to be ours. My AI needs to understand how I connect ideas. That requires me to define the structure that enforces the logic I’ve chosen.
Karpathy’s whole idea works beautifully if you start with the information architecture.
Acknowledged Gaps
Because Karpathy is speaking about systems, running in an IDE or command line and organizing markdown files with a programs like Obsidian or simple folders, it’s a little different than Notion AI.
While I’ve been able to build some very clever instructions for my Notion AI to save transcripts, including decisions, ideas, and changes, I’m still relying on it to follow the instructions or have me manually invoke a command. In Claude Code, it can be built to happen every time. Similarly, the lint system can only happen in Notion if triggered manually or using a Notion Custom Agents (which would be prohibitively expensive).
This means that while the system I’m using has a more sophisticated organizational structure, it has a less powerful system to maintain it.
But somewhere in the space between what Karpathy, a research-focused AI engineer, and I came up with is a scalable managed knowledge.
The keys are going to be out ability to build it in a way that balances accuracy and efficiency with cost. Otherwise, we’re just wasting a lot of water so we don’t need to add tags to our notes.